– Allie Mellen from Forrester wrote, “Stop trying to take humans out of security operations”
– Anton Chuvakin, ex-analyst from Gartner wrote, “Stop trying to take humans out of security operations… except… wait… wait… wait…”
– Augusto Barros, ex-analyst from Gartner wrote, “The robots are coming”
– I wrote (drawing from my Gartner days and other experiences) a series of blogs on “Demystifying the SOC”.
These are all very well-received pieces and bring interesting points of view on the topic. Most of us agree that we will not (at least for now, and likely never) completely remove humans from security operations centers (SOCs), and that the right approach is to use technology to augment people. The question then becomes — how and where to augment humans, and more broadly how to approach the SOC and how to track and measure SOC maturity.
One of the main and most visible mission of SOCs is to bring the organization back to a known, good operating state after an incident. To do so, SOCs typically operate under a process that encompasses the following phases as per the figure 1 below.

Legacy/operational maturity model for SOCs
The legacy way to look at making a SOC more autonomous is to automate as much as possible each of the phases of the SOC, from left to right, starting with collection and detection. Legacy SOC approaches are based on two wrong assumptions:
- Security is a big data problem — This is wrong, security is not a big data problem, security is a right data problem as I explained in a Gartner research note on improving threat detection.
- SOC is an ingest-based problem — This is wrong, and promotes a “garbage in/garbage out approach”. Security is an outcome-based problem, driven by what use cases are important to the business.
As a consequence of this legacy approach and wrong assumptions, many organizations first try to automatically collect as many data points as possible, often “just in case we may need it.” And then try to automatically detect as many scenarios as possible, often “just so we make sure we don’t miss anything.” And then automatically try to triage and assign as many incidents as possible, often “just so we can try and eliminate Tier 1 analysts.” Then automatically try to perform initial response across as many open cases as possible, etc.
No wonder that evolution of tools also followed a similar left-to-right, speeds and feeds-based journey. First, we had central log management (CLM) to automate collection and centralization of as many logs as possible. Then security information and event management (SIEM) to automate detection on as many scenarios as possible (most SIEM tools do a bad job at detection by the way). Then user and entity behavior analytics (UEBA) to automate detection at scale (to finally do what the SIEM vendors promised but never delivered… although most UEBA tools are still useless in deciphering what “normal” is). Then security orchestration, automation, and response (SOAR) to automate response as much as possible for all possible incidents.
This is also why the legacy metrics tracking SOC efficiency are mapped to the phases of the SOC, and are usually:
- Time-based — what is our mean time to detect (MTTD), what is our mean time to respond (MTTR), what is our mean time to answer (MTTA), etc.
- Volume-based — how many raw logs we collected, how many alerts did we generate, how many cases were open, etc.
Although these speeds and feeds-based metrics can be interesting from an operational standpoint and can sometimes be used to inform auditors that “we’re trying hard”, they fall short of describing the value of SOCs to the business. They shed no light on how strong a security posture an organization has, and they mean pretty much nothing to the C-Suite. This legacy/operational-based maturity model is described in Figure 2 below.
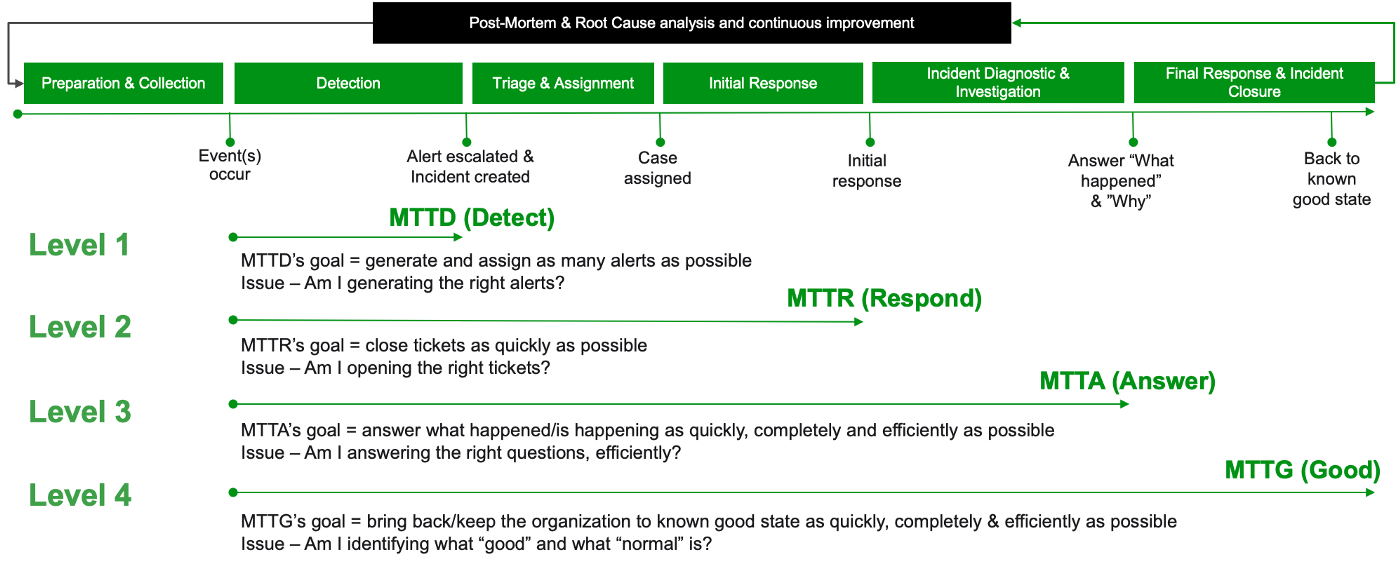
Level 1: Mean time to detect (MTTD). Level 1 maturity SOCs are focused on improving their ability to detect attacks autonomously, typically with SIEM correlation and/or with UEBA advanced analytics models.
Level 2: Mean time to respond (MTTR). Level 2 maturity SOCs are focused on improving their ability to autonomously perform the initial response to attacks, typically with SOAR playbooks. Examples include quarantining a suspiciously behaving endpoint from the network so it can be analyzed.
Level 3: Mean time to answer (MTTA). Level 3 maturity SOCs are focused on improving their ability to autonomously answer why the attack was successful. Typically organizations use tools that can accelerate threat hunting and/or presentation of normal and abnormal behavior in automated timelines of attacks across the whole organization.
Level 4: Mean time to good (MTTG). Level 4 maturity SOCs are trying to improve their ability to autonomously take all the actions to bring the organization back to the desired, known good state. It involves way more than the initial, emergency response to attacks of Level 2 MTTR. Examples include touching all the affected Windows endpoint to suspend trojan processes and clean up unsanctioned modifications to the registry and then bringing them back online.
Approaching automation from left to right (as phases described in Figures 1 and 2) and trying to improve legacy metrics will force organizations to try and automate phases sequentially without consideration of outcomes and use cases. This ingest-based approach will yield a garbage in/garbage out result, starting with inevitably too much data collected/stored without consideration of what data is needed. Then, it incentivizes SOC analysts to do the wrong thing. Some examples are:
- The best way to improve MTTD is to generate a bunch of alerts “just in case one of them is good.” But this will lead to many false positives.
- The best way to improve MTTR is to close incidents as soon as possible. But this will lead to missing key information for the MTTA and the post-mortem. As an example, when an endpoint generates alerts about an incident, managing to MTTR could lead to deciding to re-image that endpoint as quickly as possible, possibly erasing the very evidence needed to really understand what happened.
A maturity model based on speeds and feeds will promote the wrong behavior for SOC analysts and will burn people and money. For more details on why this is happening, you can read my blog on this topic.
Why not instead start with simple scenarios and use cases that we know we can solve automatically from detection all the way to final response? Start by fully automating common use cases that run autonomously, then iteratively add use cases that are more sophisticated and complex. As an example, today we know how to deal with most email phishing attacks — from detection all the way to final response, at scale, with no human involvement.
What comprises an end-to-end use case?
Historically, most security use cases have been focused on security monitoring, including threat detection, but also other scenarios such as detection of policy and compliance violations or misuse of corporate resources. These other scenarios can also be considered as threats to the organization, which provides a good framework to approach the SOC’s mission. Of course, monitoring and detection are key. But not enough, because monitoring and detecting threats is not the end goal, it is only the first step towards one of the primary goals of the SOC — to return the organization back to a known, good state after an incident.
To that end, a use case should encompass all the phases across the full lifecycle of threat detection, investigation, and response (TDIR). Its scope should be end-to-end, from collection to final response as per Figure 1. This definition of use case is much broader than the typical notion of “use case,” especially with the broader notion of “threat” that encompasses compliance violation, for example. Some examples of use cases are:
– Phishing
– Ransomware
– Compromised credentials misuse
– Lateral movement
– Privilege escalation
– Malicious insider
– Data exfiltration
– Violation of payment card information (PCI) requirement
For a SOC to address a use case, content needs to be applied prescriptively to each of the phases of TDIR. This content should ideally be turnkey and provided out of the box by security operations vendors. Example of such content is described in the diagram below.
Proper maturity model for SOCs
Once a use case is defined, SOC analysts can easily treat its full lifecycle as a continuum. Then we can introduce a maturity model that focuses on use case sophistication and complexity, based on our ability to automate this use case from end to end rather than left to right. A successful maturity model hence follows use case complexity and coverage as described below.
Level 1 SOCs typically have the ability to autonomously detect, investigate and respond to a common set of use cases that are asset and device centric such as phishing, malware, and ransomware.
Level 2 SOCs typically have the ability to autonomously detect, investigate and respond to a common set of use cases focused on compromised insiders, which is more complex to solve than asset-centric threats of Level 1.
Level 3 SOCs typically have the ability to autonomously detect, investigate and respond to a common set of use cases involving malicious insiders, which is more complex to solve than compromised credentials typical of Level 2.
Level 4 SOCs are able to autonomously address some very advanced and custom use cases. Often these use cases and scenarios are related to the business, and go way beyond cyber-hygiene use cases. Examples include fraud use cases, or supply chain attacks.
Each level up requires an enhanced level of sophistication and maturity, including more features for SOC tools and more out-of-the-box content for these tools. Across any level, the goal is to have tools that automate as many TDIR functions as possible, including not just detection, but alert validation and triage, investigation, response, and answer. Ideally full use cases can be automated end-to-end — at least starting with simple use cases that we know well. This approach frees up human time so they can focus on more complex use cases that tools cannot drive automatically. For more details on each of these levels, and to learn more about the level of sophistication for each family of use cases, you can read Part 5 of my “Demystifying the SOC” series. This approach requires:
- An outcome-based methodology
- A use case-first view of the SOC
- A SOC maturity model that is based on use case complexity and coverage
- A definition of use cases that are end-to-end, and address not only detection, but triage, investigation, and response
- Prescriptive SOC workflows and methodologies, across the full lifecycle of use cases
- Relevant content seamlessly integrated across all phases of the use cases and delivered out of the box by vendors, so organizations aren’t left trying to figure all of this out themselves
Yes, technology should be there to augment people, not replace them. But the focus should be on running use cases autonomously from detection to final response, starting with simple use cases, and then iteratively adding increasingly complex ones.
If you are interested, you can read more about this in blogs from my “Demystifying the SOC” series that I published.